
Group Relative Policy Optimization
Group Relative Policy Optimization (GRPO) is a reinforcement learning algorithm that was used to train DeepSeek-R1.


Group Relative Policy Optimization
Group Relative Policy Optimization (GRPO) is a new reinforcement learning algorithm that can be used in Reinforcement Learning (RL) for LLMs in place of Proximal Policy Optimization (PPO). In GRPO, multiple responses are generated from the same prompt using the LLM (also called policy) being trained. GRPO uses their average reward (their ‘quality’) as a baseline for computing each answer’s advantage relative to the average reward of the group; the advantage is used to calculate gradients for the policy LLM. This eliminates the need for a separate critic model (like in PPO) to calculate advantage, thereby using much less memory and compute. Like PPO, GRPO constrains the size of weight updates to prevent drastic behavior changes.
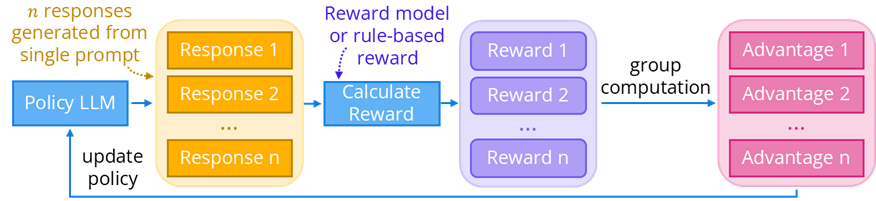
GRPO was used to train DeepSeek R1 in math and coding-based RL (using rule-based rewards) and RL from Human Feedback (RLHF). GRPO, like PPO, still depends heavily on the quality of the reward signal.
Further reading
DeepSeekMath: Pushing the Limits of Mathematical
Reasoning in Open Language Models by Shao et al. — This paper introduced GRPO. The power of the algorithm was later demonstrated in DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning by Guo et al. which introduced the DeepSeek-R1 model.
A vision researcher’s guide to some RL stuff: PPO & GRPO by Yuge Shi — This blog post explains PPO and GRPO, and covers differences between the algorithms and how they are used in RLHF.
The Transformer Reinforcement Learning (TRL) library by Hugging Face includes a GRPO Trainer. The documentation includes an example showing how to use GRPO to train a model.
Do you want to learn more NLP concepts?
Each week I pick one core NLP concept and create a one-slide, one-minute explanation of the concept. To receive weekly new posts in your inbox, subscribe here:
Reach out to me:
Connect with me on LinkedIn
Read my technical blog on Medium
Or send me a message by responding to this post
Is there a concept you would like me to cover in a future issue? Let me know!