
Knowledge Distillation
Knowledge Distillation is a popular technique for transferring knowledge from large, powerful models to smaller, more efficient models.

Knowledge Distillation
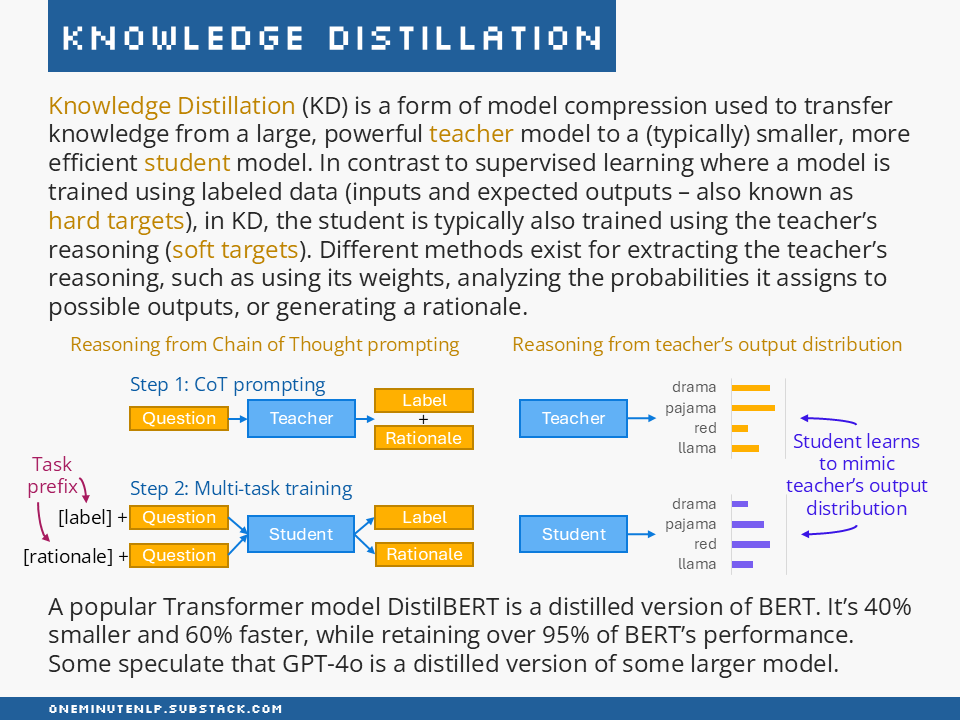
Knowledge Distillation (KD) is a form of model compression used to transfer knowledge from a large, powerful teacher model to a (typically) smaller, more efficient student model. In contrast to supervised learning where a model is trained using labeled data (inputs and expected outputs — also known as hard targets), in KD, the student is typically also trained using the teacher’s reasoning (soft targets). Different methods exist for extracting the teacher’s reasoning, such as using its weights, analyzing the probabilities it assigns to possible outputs, or generating a rationale.
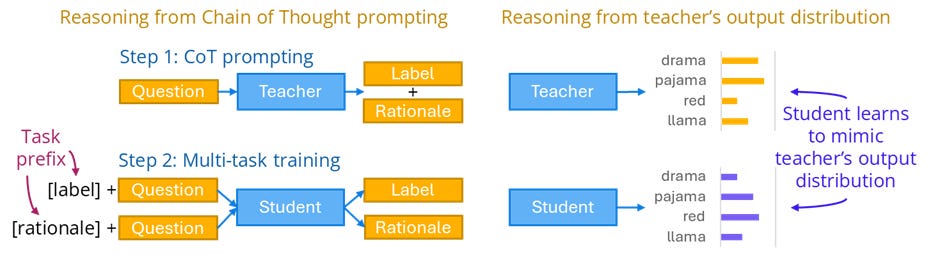
A popular Transformer model DistilBERT is a distilled version of BERT. It’s 40% smaller and 60% faster, while retaining over 95% of BERT’s performance. Some speculate that GPT-4o is a distilled version of some larger model.
Further reading
Distilling the Knowledge in a Neural Network by Hinton et al. — This seminal paper formulated the concept of knowledge distillation.
A Survey on Knowledge Distillation of Large Language Models by Xu et al. — If you want to dive deeper, this recent survey provides an overview of different methods for LLM distillation.
The SetFit library by HuggingFace for fine-tuning sentence transformers provides a Knowledge Distillation guide. OpenAI also provides an API for knowledge distillation.
Do you want to learn more NLP concepts?
Each week I pick one core NLP concept and create a one-slide, one-minute explanation of the concept. To receive weekly new posts in your inbox, subscribe here:
Reach out to me:
Connect with me on LinkedIn
Read my technical blog on Medium
Or send me a message by responding to this post
Is there a concept you would like me to cover in a future issue? Let me know!