
Low-Rank Adaptation
Low-Rank Adaptation (LoRA) is a popular method for Parameter-Efficient Fine-Tuning of Large Language Models. LoRA significantly improves fine-tuning efficiency and decreases storage requirements.

Low-Rank Adaptation
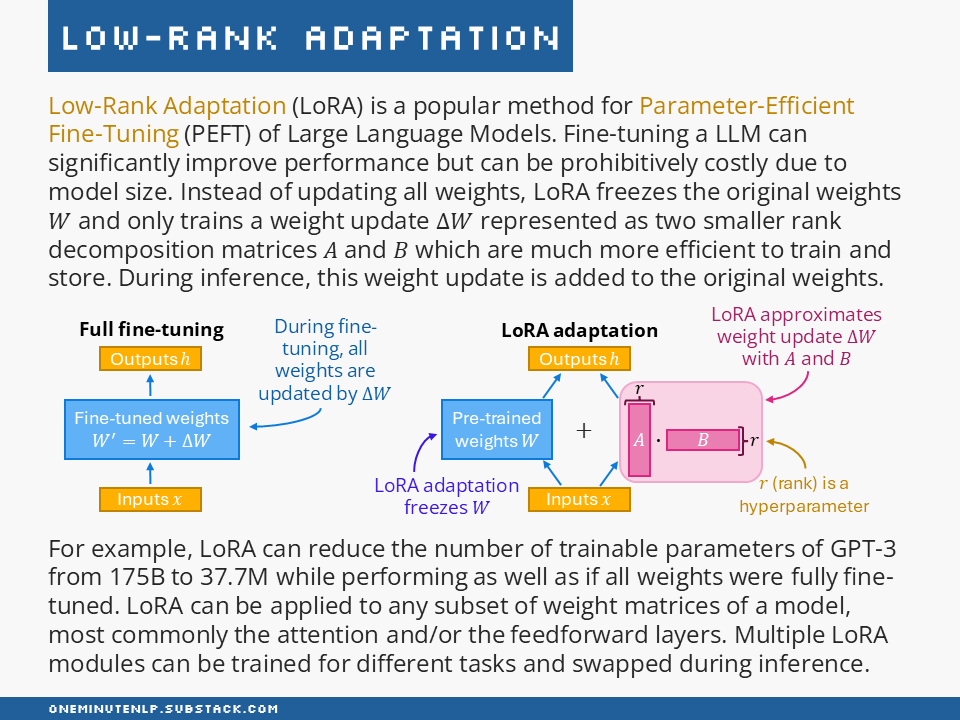
Low-Rank Adaptation (LoRA) is a popular method for Parameter-Efficient Fine-Tuning (PEFT) of Large Language Models. Fine-tuning a LLM can significantly improve performance but can be prohibitively costly due to model size. Instead of updating all weights, LoRA freezes the original weights W and only trains a weight update ΔW represented as two smaller rank decomposition matrices A and B which are much more efficient to train and store. During inference, this weight update is added to the original weights.
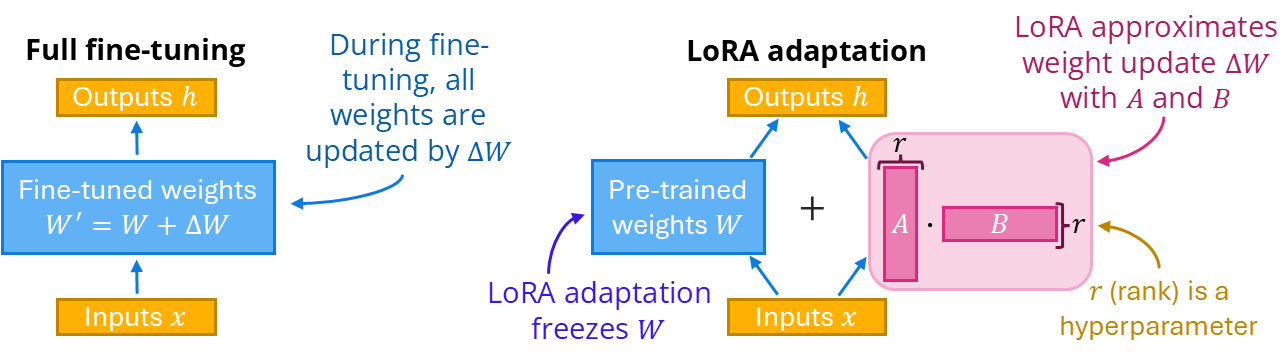
For example, LoRA can reduce the number of trainable parameters of GPT-3 from 175B to 37.7M while performing as well as if all weights were fully fine-tuned. LoRA can be applied to any subset of weight matrices of a model (most commonly the attention and/or the feedforward layers). Multiple LoRA modules can be trained for different tasks and swapped during inference.
Further Reading
LoRA: Low-Rank Adaptation of Large Language Models by Hu et al. — This paper first introduced the LoRA technique.
Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning by Lialin et al. — this paper presents a detailed survey (albeit a bit outdated) and a taxonomy of parameter-efficient fine-tuning methods.
PEFT is an implementation of various Parameter-Efficient Fine-Tuning techniques including LoRA built by Hugging Face.
Do you want to learn more NLP concepts?
Each week I pick one core NLP concept and create a one-slide, one-minute explanation of the concept. To receive weekly new posts in your inbox, subscribe here:
Reach out to me:
Connect with me on LinkedIn
Read my technical blog on Medium
Or send me a message by responding to this post
Is there a concept you would like me to cover in a future issue? Let me know!