
Mixture of Experts
Mixture of Experts (MoE) is an ensemble learning technique that enables creating larger models without increasing training and inference cost.

Mixture of Experts
Mixture of Experts (MoE) is an ensemble learning technique that trains multiple “expert” (sub-)models and a “gate” network that determines which expert(s) to use for a particular input. In Language Models, MoE is typically implemented as a sparse layer composed of multiple expert sub-layers and a router; the experts can be a simple feed forward network (FFN) or a more complex network, and the router is typically a linear layer with a softmax function. MoE enables larger models (more parameters) while still being cheap during training and inference because only a subset of the experts is active for a given input (this is called conditional computation).
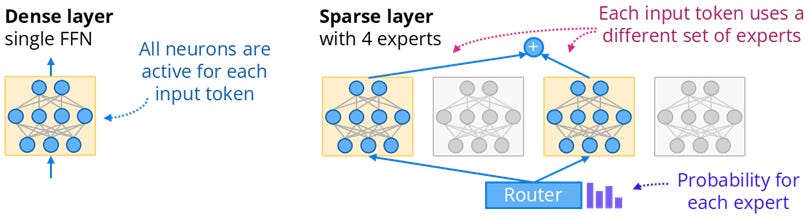
Mixtral 8x7B is an example of a MoE. In Mixtral, the feed forward layer of each transformer block is replaced by a MoE layer. Each token in a given input sequence activates a different set of experts.
Further reading
Mixture of Experts Explained by Sanseviero et al. — This article provides an overview of MoE including the history, challenges, and current developments.
A Visual Guide to Mixture of Experts (MoE) by Maarten Grootendorst — If you are a visual learner, this guide does a great job of breaking the technique down into individual components and explaining the intuition behind them.
A Survey on Mixture of Experts by Cai et al. — If you want to dive deeper, this survey covers the different ways of building MoE models.
Do you want to learn more NLP concepts?
Each week I pick one core NLP concept and create a one-slide, one-minute explanation of the concept. To receive weekly new posts in your inbox, subscribe here:
Reach out to me:
Connect with me on LinkedIn
Read my technical blog on Medium
Or send me a message by responding to this post
Is there a concept you would like me to cover in a future issue? Let me know!