
Proximal Policy Optimization
Proximal Policy Optimization is frequently used in Reinforcement Learning from Human Feedback to further train LLMs after supervised fine-tuning. It was used to train InstructGPT and ChatGPT.


Proximal Policy Optimization
Proximal Policy Optimization (PPO) is a reinforcement learning (RL) algorithm that is frequently used in Reinforcement Learning from Human Feedback (RLHF) to further train LLMs after supervised fine-tuning. In RLHF, an LLM output receives a numerical reward that represents human preference; the goal is to maximize this reward. PPO uses an actor-critic setup, training two models simultaneously. The actor (also called policy) is the LLM that generates tokens; the critic estimates the expected final reward at each token—these estimates are used to calculate gradients for the policy LLM. PPO constrains the size of weight updates on the policy LLM at each training step to prevent drastic and unpredictable behavior changes.
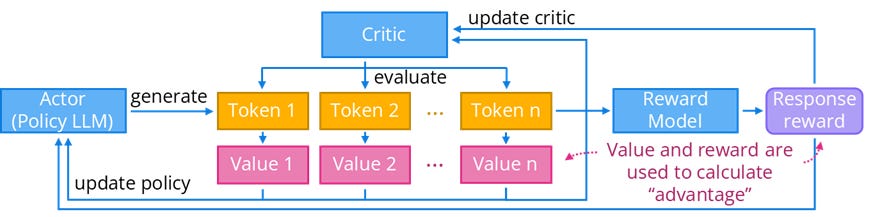
PPO is the standard algorithm for RLHF; it was used to fine-tune InstructGPT and ChatGPT. PPO doesn’t prevent reward hacking—achieving high rewards through learning to exploit imperfections in the reward model.
Further reading
These series of three posts on RL for LLMs by Cameron Wolfe do a fantastic job of explaining both the intuition and the math behind RL algorithms in an accessible way: Basics of Reinforcement Learning for LLMs, Policy Gradients: The Foundation of RLHF, Proximal Policy Optimization (PPO): The Key to LLM Alignment.
The N Implementation Details of RLHF with PPO by Costa Huang et al. — This ICLR blog post walks through a Python implementation of RLHF with PPO.
Detoxifying a Language Model using PPO by Hugging Face shows how to use the TRL (Transformer Reinforcement Learning) library to apply PPO to reduce toxicity of an LLM.
Do you want to learn more NLP concepts?
Each week I pick one core NLP concept and create a one-slide, one-minute explanation of the concept. To receive weekly new posts in your inbox, subscribe here:
Reach out to me:
Connect with me on LinkedIn
Read my technical blog on Medium
Or send me a message by responding to this post
Is there a concept you would like me to cover in a future issue? Let me know!