
RLHF
Reinforcement Learning from Human Feedback is a training phase used on LLMs after supervised fine-tuning to further improve LLM responses. It was one of the key innovations behind ChatGPT.


RLHF
Reinforcement Learning from Human Feedback (RLHF) is a training phase used on LLMs after supervised fine-tuning to further improve LLM responses. In contrast to supervised fine-tuning, where a model learns to mimic responses for given prompts, in RLHF a model learns by generating a response and then receiving a score indicating how good that response is. Because using humans to assign response scores is expensive, scores are typically generated using an LLM reward model (RM) trained on human preference pairs (prompt, winning response, losing response). RLHF uses a reinforcement learning algorithm like proximal policy optimization (PPO) to update model parameters based on the scores from the RM.
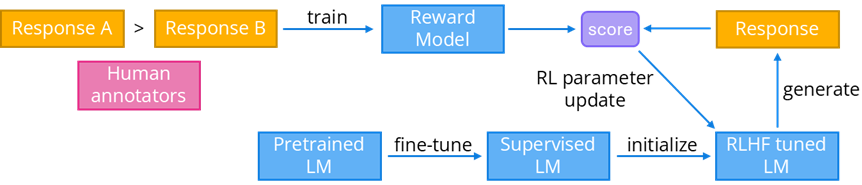
RLHF was one of key innovations behind ChatGPT. Collecting high-quality data for training a RM can be very resource intensive. RLHF is often used to improve helpfulness and minimize harmfulness of model responses.
Further reading
Learning to summarize with human feedback by Stiennon et al. and Training language models to follow instructions with human feedback by Ouyang et al. were the first works that applied RLHF to LLMs.
RLHF: Reinforcement Learning from Human Feedback by Chip Huyen — This blog post provides an easy to follow explanation of RLHF and the intuition behind it. If you want to go a bit deeper, check out The Story of RLHF: Origins, Motivations, Techniques, and Modern Applications by Cameron Wolfe.
If you prefer videos, have a look at Reinforcement Learning with Human Feedback (RLHF) in 4 minutes by Sebastian Raschka.
Do you want to learn more NLP concepts?
Each week I pick one core NLP concept and create a one-slide, one-minute explanation of the concept. To receive weekly new posts in your inbox, subscribe here:
Reach out to me:
Connect with me on LinkedIn
Read my technical blog on Medium
Or send me a message by responding to this post
Is there a concept you would like me to cover in a future issue? Let me know!