
Temperature Sampling
Temperature is a common LLM hyperparameter that controls the randomness of the model's output. This post explains how temperature sampling works.

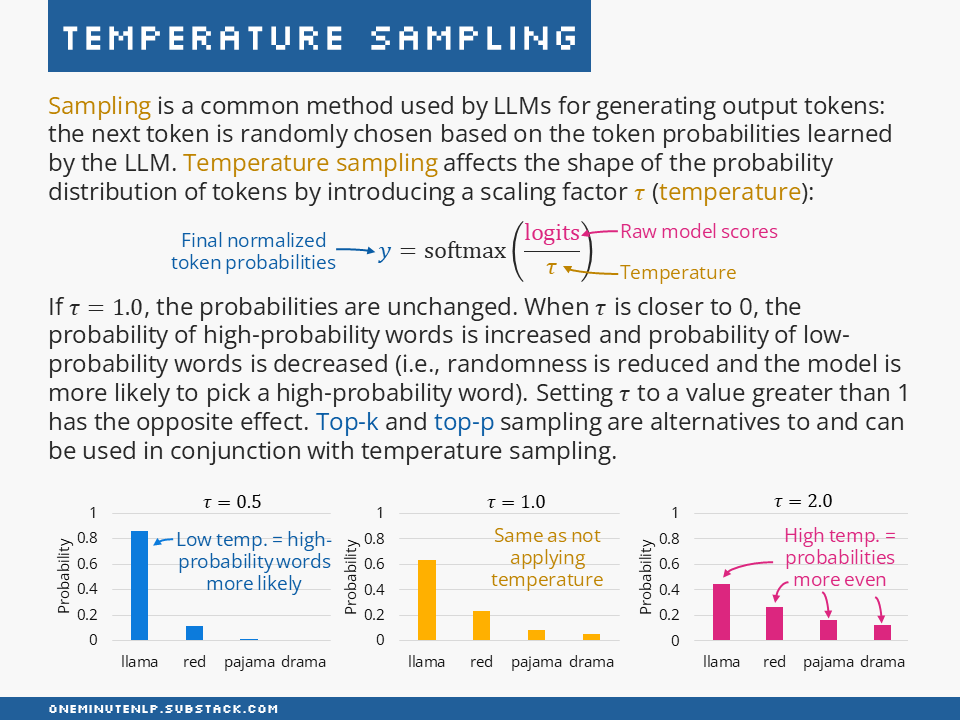
Sampling is a common method used by LLMs for generating output tokens: the next token is randomly chosen based on the token probabilities learned by the LLM. Temperature sampling affects the shape of the probability distribution of tokens by introducing a scaling factor τ (temperature):
i.e., the raw model scores are divided by τ before normalizing with softmax.
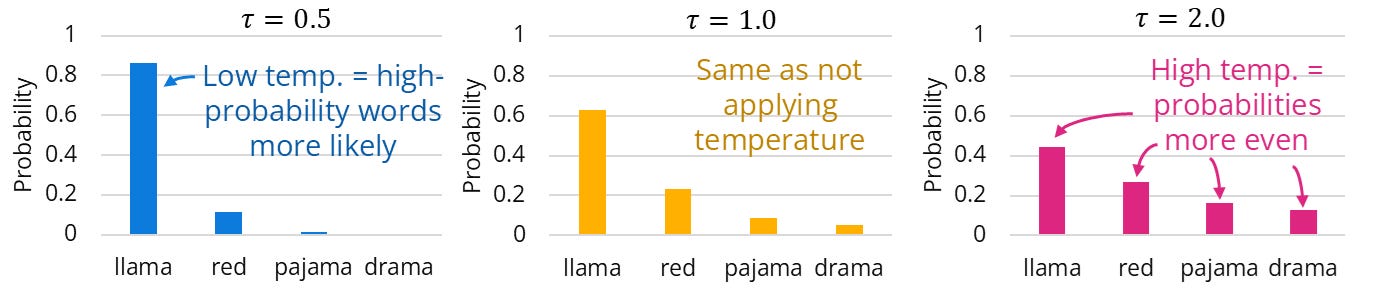
If τ=1.0, the probabilities are unchanged. When τ is closer to 0, the probability of high-probability words is increased and probability of low-probability words is decreased (i.e., randomness is reduced and the model is more likely to pick a high-probability word). Setting τ to a value greater than 1 has the opposite effect. Top-k and top-p sampling are alternatives to and can be used in conjunction with temperature sampling.
Further Reading
Your settings are (probably) hurting your model - Why sampler settings matter (reddit.com/r/LocalLLaMA post by kindacognizant) — this post provides a fantastic explanation of how different temperature values affect model outputs and how temperature works together with top-k and top-p sampling.
The Effect of Sampling Temperature on Problem Solving in Large Language Models by Renze and Guven — This recent work presents a detailed investigation of the effect of different temperature settings on LLM performance on MCQA problems.
Speech and Language Processing by Jurafsky and Martin (free to read online) — Section 10.8 (Large Language Models: Generation by Sampling) provides a great explanation of different sampling techniques.
Do you want to learn more NLP concepts?
Each week I pick one core NLP concept and create a one-slide, one-minute explanation of the concept. To receive weekly new posts in your inbox, subscribe here:
Reach out to me:
Connect with me on LinkedIn
Read my technical blog on Medium
Or send me a message by responding to this post
Is there a concept you would like me to cover in a future issue? Let me know!
should "randomness is reduced and the model is more likely to pick a high-probability word" be "randomness is reduced and the model is more likely to pick a low-probability word"?