
Top-k and top-p sampling
Top-k and top-p sampling are methods used to control the randomness and diversity of LLM outputs.


Top-k and top-p sampling
Sampling is a method LLMs use to generate output tokens, with the next token selected randomly based on learned output token probabilities. Higher-probability tokens are more likely to be chosen, but random sampling can generate odd or nonsensical outputs if low-probability tokens are picked.
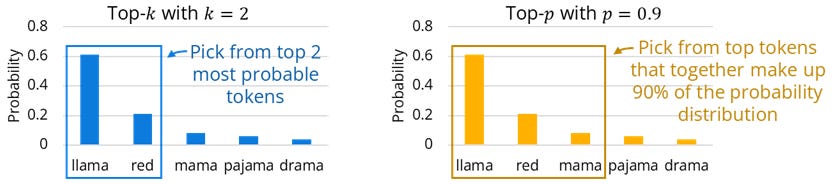
Top-k sampling truncates the distribution to the k most probable tokens, then randomly picks from this subset using renormalized probabilities. Top-1 sampling is equivalent to greedy decoding which always picks the most probable token. Top-k sampling can struggle if the top k tokens include low-probability tokens or omit likely tokens. Top-p sampling (nucleus sampling) addresses this by keeping the top p percent of the probability mass instead.
Top-k and top-p sampling can be used with or as alternatives to temperature sampling.
Further reading
Speech and Language Processing by Jurafsky and Martin (free to read online) — Section 10.8 (Large Language Models: Generation by Sampling) provides a great introduction to sampling from language models.
How to generate text: using different decoding methods for language generation with Transformers — If you prefer to learn with code, this Hugging Face blog post includes code examples alongside explanations of the most popular sampling techniques.
The Curious Case of Neural Text Degeneration by Holtzman et al. — This paper which introduced top-p sampling includes comparisons of different sampling techniques and their pros and cons.
Do you want to learn more NLP concepts?
Each week I pick one core NLP concept and create a one-slide, one-minute explanation of the concept. To receive weekly new posts in your inbox, subscribe here:
Reach out to me:
Connect with me on LinkedIn
Read my technical blog on Medium
Or send me a message by responding to this post
Is there a concept you would like me to cover in a future issue? Let me know!